My Journey to Adoption of AI
Back in 2017 or 2018, I first encountered the intense hype surrounding AI from the senior management of an organization I was working for. They firmly believed that AI would eventually replace humans, prompting discussions in the USA about how to manage a workforce rendered useless. This narrative struck me as absurd. From my perspective, the concept of AI was far from new, originating in the 1950s or 1960s. At that time, AI's capabilities seemed limited to being, at best, a partially helpful assistant.
The hype continued into 2019/2020. I recall seeing a post on LinkedIn from the CTO of an African telecom company claiming their software was being written autonomously by AI. Given the actual state of AI then, I couldn't help but feel concern for the users relying on such "autonomously written" software.
Fast forward to 2024/2025, and AI continues to be presented with considerable hyperbole, often portrayed as being close to Artificial General Intelligence (AGI). However, something has genuinely changed since those earlier days, largely fueled by the advent of powerful large language models and the public release of user-friendly interfaces like ChatGPT in late 2022. My own perception has shifted from viewing AI as offering minimal (hit or miss) support to sometimes proving to be a very useful tool or assistant. This boom has been significantly fueled by the emergence of powerful open-source models, initially from western companies like Meta (with LLaMA) and later complemented by robust contributions from Chinese open-source AI companies and their large language models, such as DeepSeek and Qwen series. This collective effort has truly made AI more accessible than ever. If used wisely, it can indeed be a great help.
In my opinion, current AI remains a highly advanced and comprehensive pattern-matching system; it is nowhere near AGI. Regarding claims that it is "very dangerous," it's true that all powerful technologies carry inherent risks. Both AI developers and law enforcement officials need to seriously consider these dangers. Imagine, for instance, handing over atomic bombs to everyone—the potential for catastrophe is obvious. Similarly, powerful tools must be used with a thorough understanding of their nature and distributed responsibly to capable individuals.
Options to use AI (Online and Offline)
AI is most often used by connecting to a cloud-based AI service provider. The most popular and pioneering is OpenAI. Many other reputable services exist, such as Gemini by Google, DeepSeek, Copilot by Microsoft, Mistral, Anthropic, and Perplexity, to name a few. Online/cloud-based AI providers are often the primary choice for utilizing AI, but for private conversations with AI, offline AI inference is the optimal solution. While "offline AI inference" might sound like a technical term, it simply refers to running AI models locally on your machine without an internet connection. Why would you want to do this? There are several benefits:
- Privacy: Your data stays on your machine, reducing the risk of data leaks.
- Offline Capability: No internet connection is needed; your AI model will still work.
- Cost-Effectiveness: For intensive or continuous use, running models locally can be more economical than recurring API fees.
- Customization: You have full control over the model and can fine-tune it for specific tasks or datasets.
Offline AI
Offline AI can be leveraged by downloading an LLM to your PC and using an inference engine to interact with it.
Understanding Local LLMs: What are LLMs?
Large Language Models (LLMs) like Meta’s LLaMA or Alibaba's Qwen or Google's Gemma are AI systems trained on vast amounts of text data. They can generate human-like responses, write code, or even summarize documents—all without needing an internet connection.
Definitions and AI Jargon
Before we dive into the setup process, let's cover some essential AI jargon:
Core Concepts
- Inference: The process of using a trained AI model to generate outputs (e.g., answering a question or writing code).
- Model Parameters: The "knowledge" stored in an AI model (e.g., a 7B model has 7 billion parameters). More parameters generally mean a smarter but slower model.
- Token: A chunk of text (e.g., a word or part of a word) that the model processes. For example, "Hello!" might split into ["Hello", "!"].
Quantization
A technique to shrink AI models by reducing numerical precision (e.g., from 32-bit to 4-bit). Think of it as compressing a high-resolution image into a smaller file—it loses some detail but runs faster on budget hardware.
- Example: A 7B model quantized to 4-bit might drop from 13GB to ~4GB with minimal quality loss.
Sampling Parameters (Control Output Quality)
- Temperature: Higher values (e.g., 0.8) make outputs random/creative; lower values (e.g., 0.2) make them deterministic/factual.
- Top-p (Nucleus Sampling): Only considers the most probable words until their combined probability reaches
p(e.g., 0.9 = top 90% of likely words). - Top-k: Limits sampling to the
kmost probable next words (e.g.,top_k=40= only pick from the top 40 options). - Min-p: Ignores words below a certain probability threshold (e.g.,
min_p=0.05= discard words with less than 5% chance).
Performance Terms
- Batch Size: Number of inputs processed at once. Higher batches speed up inference but require more RAM.
- Flash Attention: An optimization trick to speed up model inference by reducing memory usage (common in GPU setups).
My Humble Setup
Here’s the setup: You don’t need a supercomputer if you are just experimenting.
Hardware
- GMKtec M5 plus
- CPU: AMD Ryzen 7 5825U (8 cores, 16 Threads)
- Integrated GPU (iGPU): Radeon Vega 8
- RAM: 64GB DDR4-3200 (32GB x 2)
- Storage: 1TB M.2 2280 PCIe Gen 3 (for Ubuntu), 500GB M.2 2280 PCIe Gen 3 (for Windows 11)
- Networking: 2x 2.5GbE LAN, WiFi 6e, Bluetooth 5.2
- Base Power: 15W-25W (configurable)
- Total Cost: ~$420
Software
- OS: Ubuntu 22.04 LTS (for performance and availability of development tools)
I purchased and built this setup primarily to experiment and develop for myself. It wasn't solely acquired to explore AI. My main motivation for building this system was to stay within my budget while obtaining the best value for my money. The AMD Ryzen 7 5825U features a TDP (15W) while still providing decent computing performance.
If your budget allows and you're specifically looking to invest in AI, I would recommend considering a PC based on the AMD Ryzen™ AI Max+ 395, such as the GMKtec EVO-X2 AI Mini PC.
Choosing an Inference Engine
My main concern regarding using offline AI was its utility for both testing functionality and aiding my work. To use it as an aid for work, I specifically looked for options with either an Apache 2.0 or MIT license. Additionally, having a low-cost setup without any dedicated GPU, I primarily sought CPU-based inference solutions.
I searched the internet, and the first combination suggested was Ollama and Open WebUI. I tried that, but Ollama proved not very flexible in terms of model management. Additionally, Open WebUI was quite complex to set up. Furthermore, setting up Ollama for inference while using my modest iGPU required ROCm installation, which itself was 30GB and officially not supported for my iGPU. After making a few adjustments, it ended up working, which was a nice surprise.
AMD ROCm™ is an open software stack including drivers, development tools, and APIs that enable GPU programming from low-level kernel to end-user applications. For AMD GPUs, it serves as an alternative to Nvidia's CUDA.
Subsequently, I discovered the following list from Reddit (Link).
From this list, I tried the following:
- Ollama
- MSTY
- LM Studio
- Anything LLM
- Open WebUI
- TabbyAPI
- TextGen WebUI (Oobabooga)
- Kobold.cpp
- Jan
- SillyTavern
- GPT4All
My Choice of Inference Engine
I initially found LM Studio to be the best option due to its ease of setup, features and maintenance. However, during my evaluation, I discovered that LM Studio's license prohibited free use for professional purposes (This changed last month, now it is free for professional use as well). This prompted me to explore software options further.
I realized that most of the applications I had considered were based on llama.cpp. I chose to proceed with llama.cpp, which uses the GGUF format for large language models (LLMs). GGUF models can run efficiently on CPUs, making this option quite appealing.
Llama.cpp is lightweight and exceptionally fast for text tasks. The software is easy to use, as it provides pre-built binaries for Ubuntu. Additionally, it supports Vulkan-based inference, allowing me to leverage my AMD integrated GPU in conjunction with the CPU.
The llama.cpp server includes a built-in HTTP server, making it simple to interact with LLMs. In my evaluation, I found that the most versatile and user-friendly setup for low-resource systems involved using the llama.cpp server, LlamaSwap to dynamically load different models, and CherryStudio as the client. LlamaSwap enabled me to switch between models without needing to restart llama.cpp, while CherryStudio offered a clean and responsive chat interface that connected seamlessly. Moreover, it supports agents, MCP, and various other useful features.
Installing the Inference Engine and Chat Client
First, to install end-to-end setup, there are three steps to be performed:
- Install
llama.cpp - Install
llamaswap - Install
Cherry Studio
By default, llama.cpp can only load one LLM (Large Language Model). To run a different model or to run it with different settings, you need to kill the existing process and re-run the llama.cpp server with new parameters.
This problem is resolved by LlamaSwap. You can keep your individual model settings in LlamaSwap's configuration file. Your client can connect to LlamaSwap, and LlamaSwap can automatically load the appropriate model based on the query from the client.
This removes the need to manually load an LLM when switching between either different models or different settings for the same model. For example, Qwen3 had different recommended settings when you wanted to run it in "thinking mode" as compared to when you wanted to run it in "non-thinking mode."
Llama.cpp Installation Steps:
I am using Vulkan-based inference in my setup. llama.cpp provides pre-built binaries for Ubuntu. These pre-built binaries for Ubuntu include a version for CPU inference only, and another build specifically for Vulkan-based inference on Ubuntu. You can use Vulkan-based inference for most GPUs, and it is fast.
llama.cpp: Download
At the time of writing, I am using release llama-b5943-bin-ubuntu-vulkan-x64.zip.
Once the ZIP file is downloaded, you can extract it to a folder.
LlamaSwap Installation Steps:
Similar to llama.cpp, LlamaSwap also provides pre-built binaries. You can download it from the following link:
llama-swap: Download
At the time of writing, I am using llama-swap_143_linux_arm64.tar.gz.
Once the GZ archive is downloaded, extract it to the same directory where you have placed llama.cpp. While not strictly necessary, it is easier to manage.
Cherry Studio Installation Steps:
Similar to llama.cpp, Cherry Studio also provides pre-built binaries. You can download it from the following link:
cherry-studio: Download
At the time of writing, I am using Cherry-Studio-1.5.3-x86_64.AppImage.
If you do not know how to run an .AppImage file, please refer to my tech note: Run Appimage in Ubuntu.
Download a Large Language Model
My recommendation is to use models from Hugging Face, either from the Unsloth repository or the Bartowski repository.
Explore the models and download the GGUF files to your desired folder on your PC. There are many Apache 2.0 or MIT license LLMs.
End-to-End Workflow: Text Input-Text Output Inference
To make this setup end-to-end operational, you need to configure LlamaSwap to load models through llama.cpp and use Cherry Studio to connect to LlamaSwap.
I have created .desktop files to show LlamaSwap and Cherry Studio in my app menu. The configurations are provided below.
- CherryStudio
- LlamaSwap
[Desktop Entry]
Name=CherryStudio
Exec=/home/tipu/Applications/Cherry-Studio.AppImage %U
Icon=/home/tipu/icons/cherrystudio.png
Type=Application
Categories=Development;Utility;
[Desktop Entry]
Name=Llama Swap
Comment=Launch Llama Swap in terminal
Exec=gnome-terminal --working-directory=/home/tipu/Applications/llamacpp/ -- bash -c "./llama-swap --config config.yaml --listen :8888 --watch-config; exec bash"
Icon=utilities-terminal
Terminal=false
Type=Application
Categories=Development;
The next step is to configure LlamaSwap. I'm sharing my configuration, which you can use if you're working with the same models.
LlamaSwap Configuration File
# Seconds to wait for llama.cpp to be available to serve requests
# Default (and minimum): 15 seconds
healthCheckTimeout: 120
# valid log levels: debug, info (default), warn, error
logLevel: debug
groups:
# group1 is same as the default behaviour of llama-swap where only one model is allowed
# to run a time across the whole llama-swap instance
"Other":
# swap: controls the model swapping behaviour in within the group
# - optional, default: true
# - true : only one model is allowed to run at a time
# - false: all models can run together, no swapping
swap: true
# exclusive: controls how the group affects other groups
# - optional, default: true
# - true: causes all other groups to unload when this group runs a model
# - false: does not affect other groups
exclusive: true
# members references the models defined above
# required
members:
- "DeepSeek-R1-0528-8B"
- "Devstral-Small-2505"
- "THUDM_GLM-4-9B-0414"
- "Tesslate_Tessa-Rust-T1-7B"
- "Hunyuan-A13B-Instruct-Thinking"
- "Hunyuan-A13B-Instruct-Non-Thinking"
"Gemma3":
# swap: controls the model swapping behaviour in within the group
# - optional, default: true
# - true : only one model is allowed to run at a time
# - false: all models can run together, no swapping
swap: true
# exclusive: controls how the group affects other groups
# - optional, default: true
# - true: causes all other groups to unload when this group runs a model
# - false: does not affect other groups
exclusive: true
# members references the models defined above
# required
members:
- "Gemma3-4B"
- "Gemma3-12B"
"Nanonets-OCR":
# swap: controls the model swapping behaviour in within the group
# - optional, default: true
# - true : only one model is allowed to run at a time
# - false: all models can run together, no swapping
swap: true
# exclusive: controls how the group affects other groups
# - optional, default: true
# - true: causes all other groups to unload when this group runs a model
# - false: does not affect other groups
exclusive: true
# members references the models defined above
# required
members:
- "Nanonets-OCR"
"Qwen3-30B-A3B":
# swap: controls the model swapping behaviour in within the group
# - optional, default: true
# - true : only one model is allowed to run at a time
# - false: all models can run together, no swapping
swap: true
# exclusive: controls how the group affects other groups
# - optional, default: true
# - true: causes all other groups to unload when this group runs a model
# - false: does not affect other groups
exclusive: true
# members references the models defined above
# required
members:
- "Qwen-A3B-Q4-Thinking"
- "Qwen-A3B-Q6-Thinking"
- "Qwen-A3B-Q4-No-Thinking"
- "Qwen-A3B-Q6-No-Thinking"
macros:
"llama-cpp": >
/home/tipu/Applications/llamacpp/llama-server
--port ${PORT}
--api-key 12345
models:
"Qwen-A3B-Q4-Thinking":
# cmd: the command to run to start the inference server.
# - required
# - it is just a string, similar to what you would run on the CLI
# - using `|` allows for comments in the command, these will be parsed out
# - macros can be used within cmd
cmd: |
${llama-cpp}
-m /home/tipu/.lmstudio/models/unsloth/Qwen3-30B-A3B-GGUF/Qwen3-30B-A3B-128K-UD-Q4_K_XL.gguf
--jinja
--reasoning-format none
-n -1
-ngl 99
--temp 0.6
--top-k 20
--top-p 0.95
--min-p 0
-c 10240
--no-context-shift
--mlock
--ubatch-size 128
--batch-size 2048
--seed -1
-t 4
-fa
--no-mmap
--no-warmup
--presence-penalty 1.1
-a Qwen-A3B-Q4-Thinking
--no-webui
# env: define an array of environment variables to inject into cmd's environment
# - optional, default: empty array
# - each value is a single string
# - in the format: ENV_NAME=value
#env:
# - "CUDA_VISIBLE_DEVICES=0,1,2"
# proxy: the URL where llama-swap routes API requests
# - optional, default: http://localhost:${PORT}
# - if you used ${PORT} in cmd this can be omitted
# - if you use a custom port in cmd this *must* be set
#proxy: http://127.0.0.1:8999
# aliases: alternative model names that this model configuration is used for
# - optional, default: empty array
# - aliases must be unique globally
# - useful for impersonating a specific model
aliases:
- "Qwen-A3B-Q4-Thinking"
# checkEndpoint: URL path to check if the server is ready
# - optional, default: /health
# - use "none" to skip endpoint ready checking
# - endpoint is expected to return an HTTP 200 response
# - all requests wait until the endpoint is ready (or fails)
#checkEndpoint: /custom-endpoint
# ttl: automatically unload the model after this many seconds
# - optional, default: 0
# - ttl values must be a value greater than 0
# - a value of 0 disables automatic unloading of the model
ttl: 120
# useModelName: overrides the model name that is sent to upstream server
# - optional, default: ""
# - useful when the upstream server expects a specific model name or format
useModelName: "Qwen-A3B-Q4-Thinking"
# filters: a dictionary of filter settings
# - optional, default: empty dictionary
filters:
# strip_params: a comma separated list of parameters to remove from the request
# - optional, default: ""
# - useful for preventing overriding of default server params by requests
# - `model` parameter is never removed
# - can be any JSON key in the request body
# - recommended to stick to sampling parameters
strip_params: "temperature, top_p, top_k, min-p, min-k"
"Qwen-A3B-Q6-Thinking":
# cmd: the command to run to start the inference server.
# - required
# - it is just a string, similar to what you would run on the CLI
# - using `|` allows for comments in the command, these will be parsed out
# - macros can be used within cmd
cmd: |
${llama-cpp}
-m /home/tipu/.lmstudio/models/unsloth/Qwen3-30B-A3B-GGUF/Qwen3-30B-A3B-128K-UD-Q6_K_XL.gguf
--jinja
--reasoning-format none
-n -1
-ngl 99
--temp 0.6
--top-k 20
--top-p 0.95
--min-p 0
-c 10240
--no-context-shift
--mlock
--ubatch-size 128
--batch-size 2048
--seed -1
-t 4
-fa
--no-mmap
--no-warmup
--presence-penalty 1.1
-a Qwen-A3B-Q6-Thinking
--no-webui
# env: define an array of environment variables to inject into cmd's environment
# - optional, default: empty array
# - each value is a single string
# - in the format: ENV_NAME=value
#env:
# - "CUDA_VISIBLE_DEVICES=0,1,2"
# proxy: the URL where llama-swap routes API requests
# - optional, default: http://localhost:${PORT}
# - if you used ${PORT} in cmd this can be omitted
# - if you use a custom port in cmd this *must* be set
#proxy: http://127.0.0.1:8999
# aliases: alternative model names that this model configuration is used for
# - optional, default: empty array
# - aliases must be unique globally
# - useful for impersonating a specific model
aliases:
- "Qwen-A3B-Q6-Thinking"
# checkEndpoint: URL path to check if the server is ready
# - optional, default: /health
# - use "none" to skip endpoint ready checking
# - endpoint is expected to return an HTTP 200 response
# - all requests wait until the endpoint is ready (or fails)
#checkEndpoint: /custom-endpoint
# ttl: automatically unload the model after this many seconds
# - optional, default: 0
# - ttl values must be a value greater than 0
# - a value of 0 disables automatic unloading of the model
ttl: 120
# useModelName: overrides the model name that is sent to upstream server
# - optional, default: ""
# - useful when the upstream server expects a specific model name or format
useModelName: "Qwen-A3B-Q6-Thinking"
# filters: a dictionary of filter settings
# - optional, default: empty dictionary
filters:
# strip_params: a comma separated list of parameters to remove from the request
# - optional, default: ""
# - useful for preventing overriding of default server params by requests
# - `model` parameter is never removed
# - can be any JSON key in the request body
# - recommended to stick to sampling parameters
strip_params: "temperature, top_p, top_k, min-p, min-k"
"Qwen-A3B-Q4-No-Thinking":
# cmd: the command to run to start the inference server.
# - required
# - it is just a string, similar to what you would run on the CLI
# - using `|` allows for comments in the command, these will be parsed out
# - macros can be used within cmd
cmd: |
${llama-cpp}
-m /home/tipu/.lmstudio/models/unsloth/Qwen3-30B-A3B-GGUF/Qwen3-30B-A3B-128K-UD-Q4_K_XL.gguf
--jinja
--reasoning-budget 0
-n -1
-ngl 99
--temp 0.7
--top-k 20
--top-p 0.8
--min-p 0
-c 10240
--no-context-shift
--mlock
--no-mmap
--no-warmup
--ubatch-size 128
--batch-size 2048
--seed -1
-t 4
-fa
--presence-penalty 1.1
-a Qwen-A3B-Q4-No-Thinking
--no-webui
# env: define an array of environment variables to inject into cmd's environment
# - optional, default: empty array
# - each value is a single string
# - in the format: ENV_NAME=value
#env:
# - "CUDA_VISIBLE_DEVICES=0,1,2"
# proxy: the URL where llama-swap routes API requests
# - optional, default: http://localhost:${PORT}
# - if you used ${PORT} in cmd this can be omitted
# - if you use a custom port in cmd this *must* be set
#proxy: http://127.0.0.1:8999
# aliases: alternative model names that this model configuration is used for
# - optional, default: empty array
# - aliases must be unique globally
# - useful for impersonating a specific model
aliases:
- "Qwen-A3B-Q4-No-Thinking"
# checkEndpoint: URL path to check if the server is ready
# - optional, default: /health
# - use "none" to skip endpoint ready checking
# - endpoint is expected to return an HTTP 200 response
# - all requests wait until the endpoint is ready (or fails)
#checkEndpoint: /custom-endpoint
# ttl: automatically unload the model after this many seconds
# - optional, default: 0
# - ttl values must be a value greater than 0
# - a value of 0 disables automatic unloading of the model
ttl: 120
# useModelName: overrides the model name that is sent to upstream server
# - optional, default: ""
# - useful when the upstream server expects a specific model name or format
useModelName: "Qwen-A3B-Q4-No-Thinking"
# filters: a dictionary of filter settings
# - optional, default: empty dictionary
filters:
# strip_params: a comma separated list of parameters to remove from the request
# - optional, default: ""
# - useful for preventing overriding of default server params by requests
# - `model` parameter is never removed
# - can be any JSON key in the request body
# - recommended to stick to sampling parameters
strip_params: "temperature, top_p, top_k, min-p, min-k"
"Qwen-A3B-Q6-No-Thinking":
# cmd: the command to run to start the inference server.
# - required
# - it is just a string, similar to what you would run on the CLI
# - using `|` allows for comments in the command, these will be parsed out
# - macros can be used within cmd
cmd: |
${llama-cpp}
-m /home/tipu/.lmstudio/models/unsloth/Qwen3-30B-A3B-GGUF/Qwen3-30B-A3B-128K-UD-Q6_K_XL.gguf
--jinja
--reasoning-budget 0
-n -1
-ngl 99
--temp 0.7
--top-k 20
--top-p 0.8
--min-p 0
-c 10240
--no-context-shift
--mlock
--no-mmap
--no-warmup
--ubatch-size 128
--batch-size 2048
--seed -1
-t 4
-fa
--presence-penalty 1.1
-a Qwen-A3B-Q6-No-Thinking
--no-webui
# env: define an array of environment variables to inject into cmd's environment
# - optional, default: empty array
# - each value is a single string
# - in the format: ENV_NAME=value
#env:
# - "CUDA_VISIBLE_DEVICES=0,1,2"
# proxy: the URL where llama-swap routes API requests
# - optional, default: http://localhost:${PORT}
# - if you used ${PORT} in cmd this can be omitted
# - if you use a custom port in cmd this *must* be set
#proxy: http://127.0.0.1:8999
# aliases: alternative model names that this model configuration is used for
# - optional, default: empty array
# - aliases must be unique globally
# - useful for impersonating a specific model
aliases:
- "Qwen-A3B-Q6-No-Thinking"
# checkEndpoint: URL path to check if the server is ready
# - optional, default: /health
# - use "none" to skip endpoint ready checking
# - endpoint is expected to return an HTTP 200 response
# - all requests wait until the endpoint is ready (or fails)
#checkEndpoint: /custom-endpoint
# ttl: automatically unload the model after this many seconds
# - optional, default: 0
# - ttl values must be a value greater than 0
# - a value of 0 disables automatic unloading of the model
ttl: 120
# useModelName: overrides the model name that is sent to upstream server
# - optional, default: ""
# - useful when the upstream server expects a specific model name or format
useModelName: "Qwen-A3B-Q6-No-Thinking"
# filters: a dictionary of filter settings
# - optional, default: empty dictionary
filters:
# strip_params: a comma separated list of parameters to remove from the request
# - optional, default: ""
# - useful for preventing overriding of default server params by requests
# - `model` parameter is never removed
# - can be any JSON key in the request body
# - recommended to stick to sampling parameters
strip_params: "temperature, top_p, top_k, min-p, min-k"
"Gemma3-4B":
cmd: |
${llama-cpp}
-m /home/tipu/.lmstudio/models/unsloth/gemma3-4B/gemma-3-4b-it-UD-Q5_K_XL.gguf
--mmproj /home/tipu/.lmstudio/models/unsloth/gemma3-4B/mmproj-BF16.gguf
--jinja
-n -1
-ngl 99
--repeat-penalty 1.0
--min-p 0.01
--top-k 64
--top-p 0.95
-t 4
--no-webui
-a Gemma3-4B
-c 10240
--no-context-shift
--mlock
--no-mmap
--no-warmup
--seed 3501
--swa-full
aliases:
- "Gemma3-4B"
ttl: 120
useModelName: "Gemma3-4B"
filters:
strip_params: "temperature, top_p, top_k, min-p, min-k"
"Gemma3-12B":
cmd: |
${llama-cpp}
-m /home/tipu/.lmstudio/models/unsloth/gemma3_12B/gemma-3-12b-it-UD-Q5_K_XL.gguf
--mmproj /home/tipu/.lmstudio/models/unsloth/gemma3_12B/mmproj-BF16.gguf
--jinja
-n -1
-ngl 99
--repeat-penalty 1.0
--min-p 0.01
--top-k 64
--top-p 0.95
-t 4
--no-mmap
--no-warmup
--no-webui
-a Gemma3-12B
-c 10240
--no-context-shift
--mlock
--seed 3503
--swa-full
aliases:
- "Gemma3-12B"
ttl: 120
useModelName: "Gemma3-12B"
filters:
strip_params: "temperature, top_p, top_k, min-p, min-k"
"Nanonets-OCR":
cmd: |
${llama-cpp}
-m /home/tipu/.lmstudio/models/unsloth/Nanonets-OCR/Nanonets-OCR-s-Q8_0.gguf
--mmproj /home/tipu/.lmstudio/models/unsloth/Nanonets-OCR/nanonets-mmproj-F16.gguf
-n -1
-ngl 99
--jinja
--repeat-penalty 1.1
--temp 0.0
--min-p 0.01
-t 4
--no-webui
-a Nanonets-OCR
-c 10240
--ubatch-size 128
--batch-size 2048
--mlock
--seed -1
--swa-full
--no-escape
-fa
--no-mmap
--no-warmup
aliases:
- "Nanonets-OCR"
ttl: 120
useModelName: "Nanonets-OCR"
filters:
strip_params: "temperature, top_p, top_k, min-p, min-k"
"Devstral-Small-2505":
cmd: |
${llama-cpp}
-m /home/tipu/.lmstudio/models/unsloth/Devstral-Small-2505/Devstral-Small-2505-UD-Q5_K_XL.gguf
--jinja
-n -1
-ngl 99
--repeat-penalty 1.0
--temp 0.15
--top-p 0.95
--min-p 0.01
--top-k 40
-t 4
--ubatch-size 128
--batch-size 2048
--no-webui
-a Devstral-Small-2505
-c 10240
--no-context-shift
--mlock
-fa
--no-mmap
--no-warmup
aliases:
- "Devstral-Small-2505"
ttl: 120
useModelName: "Devstral-Small-2505"
filters:
strip_params: "temperature, top_p, top_k, min-p, min-k"
"DeepSeek-R1-0528-8B":
cmd: |
${llama-cpp}
-m /home/tipu/.lmstudio/models/unsloth/DeepSeek-R1-0528-8B-GGUF/DeepSeek-R1-0528-Qwen3-8B-UD-Q6_K_XL.gguf
--jinja
-n -1
-ngl 99
--repeat-penalty 1.05
--temp 0.6
--top-p 0.95
--min-p 0.00
--top-k 20
-t 4
--no-webui
-a DeepSeek-R1-0528-8B
-c 10240
--no-context-shift
--mlock
--ubatch-size 128
--batch-size 2048
-fa
--no-mmap
--no-warmup
aliases:
- "DeepSeek-R1-0528-8B"
ttl: 120
useModelName: "DeepSeek-R1-0528-8B"
filters:
strip_params: "temperature, top_p, top_k, min-p, min-k"
"THUDM_GLM-4-9B-0414":
cmd: |
${llama-cpp}
-m /home/tipu/.lmstudio/models/unsloth/GLM-4-9B-0414/GLM-4-9B-0414-UD-Q5_K_XL.gguf
--jinja
-n -1
--temp 0.2
--top-p 1
--min-p 0.01
-ngl 99
-t 4
--no-webui
-a THUDM_GLM-4-9B-0414
-c 10240
--no-context-shift
--ubatch-size 128
--batch-size 2048
--mlock
-fa
--swa-full
--no-mmap
--no-warmup
aliases:
- "THUDM_GLM-4-9B-0414"
ttl: 120
useModelName: "THUDM_GLM-4-9B-0414"
filters:
strip_params: "temperature, top_p, top_k, min-p, min-k"
"Tesslate_Tessa-Rust-T1-7B":
cmd: |
${llama-cpp}
-m /home/tipu/.lmstudio/models/bartowski/Tesslate_Tessa-Rust-T1-7B-GGUF/Tesslate_Tessa-Rust-T1-7B-Q6_K_L.gguf
--jinja
-n -1
-ngl 99
-t 4
--temp 0.2
--top-p 1
--min-p 0.01
--no-webui
-a Tesslate_Tessa-Rust-T1-7B
-c 10240
--no-context-shift
--mlock
-fa
--no-mmap
--no-warmup
aliases:
- "Tesslate_Tessa-Rust-T1-7B"
ttl: 120
useModelName: "Tesslate_Tessa-Rust-T1-7B"
filters:
strip_params: "temperature, top_p, top_k, min-p, min-k"
"Hunyuan-A13B-Thinking":
cmd: |
${llama-cpp}
-m /home/tipu/.lmstudio/models/unsloth/Hunyuan-A13B-Instruct/Hunyuan-A13B-Instruct-IQ4_XS.gguf
--jinja
--reasoning-format none
--reasoning-budget -1
-n -1
-ngl 7
--temp 0.7
--top-k 20
--top-p 0.8
--repeat-penalty 1.05
-c 4096
--seed -1
-t 4
-fa
--mlock
--no-warmup
--ubatch-size 128
--batch-size 2048
-a Hunyuan-A13B-Thinking
--no-webui
--no-kv-offload
--cache-type-k q8_0
--cache-type-v q8_0
aliases:
- "Hunyuan-A13B-Thinking"
ttl: 120
useModelName: "Hunyuan-A13B-Thinking"
filters:
strip_params: "temperature, top_p, top_k, min-p, min-k, reasoning-budget"
"Hunyuan-A13B-Non-Thinking":
cmd: |
${llama-cpp}
-m /home/tipu/.lmstudio/models/unsloth/Hunyuan-A13B-Instruct/Hunyuan-A13B-Instruct-IQ4_XS.gguf
--jinja
--reasoning-format none
--reasoning-budget 0
-n -1
-ngl 7
--temp 0.5
--top-k 20
--top-p 0.7
--repeat-penalty 1.05
-c 4096
--seed -1
-t 4
-fa
--mlock
--no-warmup
-a Hunyuan-A13B-Non-Thinking
--no-webui
--ubatch-size 128
--batch-size 2048
--no-kv-offload
--cache-type-k q8_0
--cache-type-v q8_0
aliases:
- "Hunyuan-A13B-Non-Thinking"
ttl: 120
useModelName: "Hunyuan-A13B-Non-Thinking"
filters:
strip_params: "temperature, top_p, top_k, min-p, min-k, reasoning-budget"
# don't use these, just for testing if things are broken
"broken":
cmd: models/llama-server-osx --port 8999 -m models/doesnotexist.gguf
proxy: http://127.0.0.1:8999
unlisted: true
"broken_timeout":
cmd: models/llama-server-osx --port 8999 -m models/qwen2.5-0.5b-instruct-q8_0.gguf
proxy: http://127.0.0.1:9000
unlisted: true
Then you need to go to Cherry Studio. Go to settings > Model Provider and create a new entry as shown below.
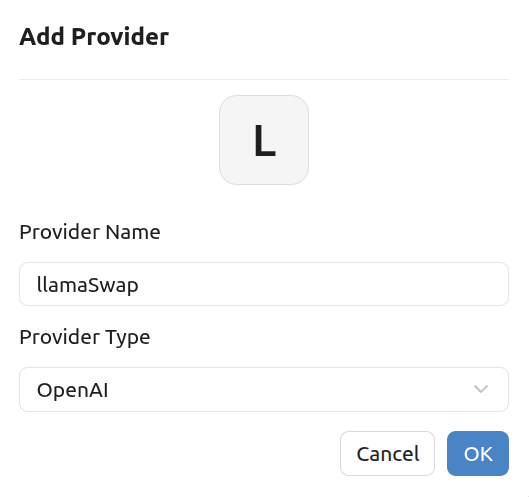
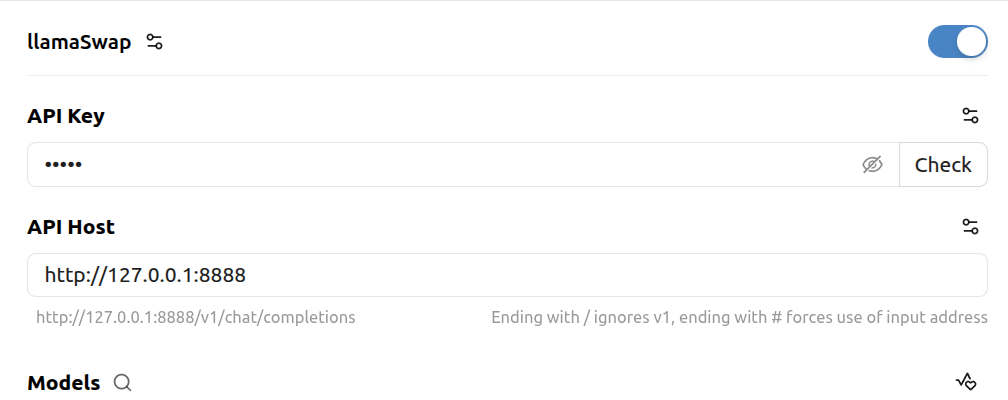
After that, edit the entry to enter the local URL with the port as configured in LlamaSwap's config.yaml. Also, enter the API key if you've configured one in llama.cpp. equire
Chat Application
Based on my setup, I have been able to run a dense 24B-parameter model (Mistral: Devstral Small) quantized at Q4, achieving 2.3 tokens/second.
Additionally, Mixture of Experts (MoE) models are available. With an MoE model, I can run an 80B model (Hunyuan-A13B-Thinking) quantized at Q4, achieving 4 tokens/sec. (Below screenshot in bottom left corner shows token per second.)


My favorite is Qwen-A3B (Qwen-A3B-Q4-No-Thinking), which features 3B active parameters and a total of 30B parameters. On average, I can run it at 16 tokens/sec. (Below screenshot in bottom left corner shows token per second.)


Coding Assistant
LlamaSwap does not implement all OpenAI-compatible endpoints. You can run the llama.cpp server and chat through the continue.dev extension in VS Code.
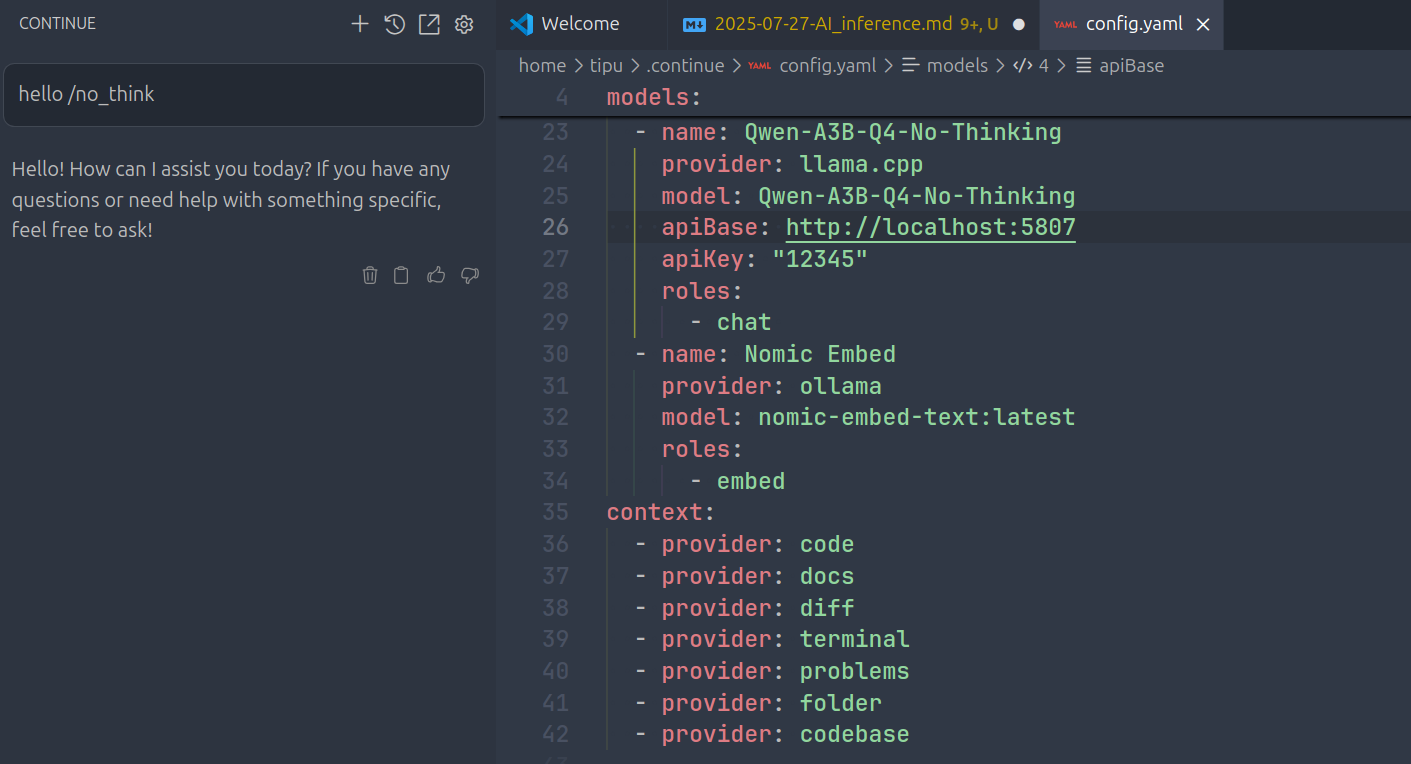
Similarly, you can use Openhands and Qwen3 Coder directly with the llama.cpp server.
Conclusion: Embracing the Feasibility of Offline AI
Running AI locally is feasible, it can be empowering. With a decent PC and the right tools, you can access a world of privacy-focused, customizable AI applications for assistance and learning.
Happy learning!